📢 声明
本文使用包括 Mistral 和 GPT 在内的 LLM 辅助撰写,但作者为所有内容负责。
为什么要写这篇博客?
自从生成式人工智能 (Generative Artificial Intelligence, Gen-AI) 的诞生之初,人们对它们的讨论就没有停止过。有赞许的声音,也有批评的声音;有的人对 AI 的前景表示乐观,也有的人对人类的前景表示悲观。还有人,因为缺乏对相关技术原理的理解,对它们带有很大的偏见,而这种偏见在信息茧房和互联网的透镜作用下进一步放大,从而导致了普遍的错误认知。
尤其是在 AI 绘画领域,很多画师和观众因为缺乏对技术原理的基本认知而盲目跟风抵制或者空口鉴图(我不是说抵制是错误的,在后文我会谈到我们为什么要抵制 AI 绘画),我认为这种现象对绘画界、乃至艺术界并不是有益的。即使我们要把 AI 绘画当作敌人,我们也应该首先了解它;更何况 AI 绘画并不是十恶不赦的魔鬼造物,只要使用得当它也可以作为趁手的辅助工具来推动绘画技术的发展。
知己知彼,方能百战不殆。
——《孙子·谋攻》
如果您正在看这篇文章并已经怒不可遏,我请求您耐着性子看完。这或许会让您对 AI 绘画有一个更全面的认识;在那之后,您可以继续抵制,也可以转变立场,还可以在评论区或者发邮件(见侧栏)骂我。
AI 绘画到底是什么?
首先,我们来捋一捋 AI 绘画的发展历程。如果想直接了解当下的 AI 绘画技术,可以直接跳到扩散式生成模型:2021 年。
一切的起源:1973 年
在 1973 年,Harold Cohen 教授开始了他的 AARON 项目,这是一个旨在研究计算机绘画的项目。AARON 是一个能够自主创作绘画作品的程序,它能够根据自己的程序逻辑和一些随机因素来创作绘画作品。AARON 的绘画风格主要是抽象的,但是它的作品在当时已经引起了很大的轰动。AARON 的绘画作品被展示在了世界各地的画廊和博物馆,甚至有一些作品被收藏在了博物馆的永久藏品中。
AARON 无法自行学习新的风格或图像;每种新功能都必须由科恩手工编码。AARON 能够以自己的风格制作出几乎无穷无尽的独特图像。这些图像已在世界各地的画廊展出。AARON 的作品被用作图灵测试的艺术等价物。不过,AARON 的输出似乎遵循一个明显的公式(站在盆栽旁的人物、彩色方框是一个共同的主题)。科恩非常谨慎,没有声称 AARON 具有创造性。但他确实在问:“如果 AARON 制作的不是艺术,那它到底是什么,除了它的起源,它在哪些方面与‘真实的东西’不同?如果它不是在思考,那它到底在做什么?” [^1]
深度学习时代:2014 年
2014 年,Ian Goodfellow 等人提出了生成式对抗网络(Generative Adversarial Networks, GANs)的概念。GANs 是一种深度学习模型,它由两个神经网络组成:生成器(Generator)和判别器(Discriminator)。生成器的任务是生成尽可能逼真的图像,而判别器的任务是判断图像是真实的还是生成的。生成器和判别器通过对抗训练的方式来提高自己的性能,最终生成器可以生成逼真的图像。[^2]
GANs 的出现使得 AI 绘画的发展进入了一个新的阶段。在 GANs 的基础上,研究人员提出了很多变种模型,如 StyleGAN、BigGAN、CycleGAN 等。这些模型在生成逼真图像的同时,也为 AI 绘画的发展提供了更多的可能性。
扩散式生成模型:2021 年
扩散模型的概念最早在 2015 年就已经被 Sohl-Dickstein 等人提出。它是一种无监督学习模型,通过模拟非平衡热力学过程来学习数据的分布。[^3]但是直到 2021 年,扩散式生成模型才开始大规模地应用于图像生成领域。
扩散式生成模型的原理
我们来了解一下扩散模型是如何运作的——我尽量不使用任何高端的术语,以便大家能够更好地理解。
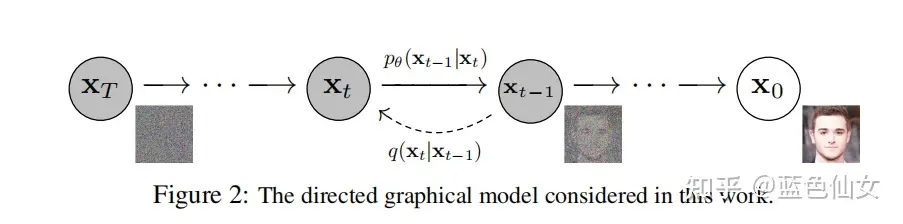
在上面的示意图中,我们可以看到从右边到左边的过程。在最右边 $\mathrm x_0$ 的地方我们有一张清晰的图像,然后我们通过一系列的扩散操作(就像水波扩散一样)来逐渐向图像中添加噪声,最终得到一张几乎完全是噪声的图像 $\mathrm x_T$。
如果我们把这个过程反过来,让机器学习到如何从一张几乎完全是噪声的图像 $\mathrm x_T$ 逐渐还原到一张清晰的图像 $\mathrm x_0$,那么我们就可以得到一个扩散式的生成模型。稍微做一个不严谨的比喻,这个过程就像是我们从一张马赛克图像中逐渐脑补出更高清的马赛克,直到最终得到一张清晰的图像。
再向前述两个过程中加入文字描述的部分,作为过程的参考。只要有足够的训练数据,我们就可以让机器学会如何根据所给的文字描述,从几乎完全是噪声的图像还原到一张清晰的图像。
这就是扩散式图片生成模型的基本原理。
缺点
扩散式生成模型的缺点在于生成的图像往往会有一些细节上的问题,比如人物的手、头发、阴影关系可能会画得不太好。说到底,扩散式生成模型是一个通过逐渐还原噪声图像来生成清晰图像的模型,它不是通过理解图像的组成部分、并进行重建或渲染来生成图像的。
此外,扩散式生成模型的训练和推理都需要大量的计算资源。尤其是在推理应用中——如果我们想要在可以接受的时间内生成一张图像,只有两种办法:要么使用强大而且昂贵的硬件,要么降低图像的质量——而后者正是大多数情况下的选择。
常见误区
尸块?
我们经常可以看到AI 绘画就是拼尸块这样的说法。在阅读上面的原理之后,我们能够很容易地理解到这种说法的错误之处:扩散式生成模型并不是简单地将一张图像分割成若干块,然后随机地拼接在一起;它们是通过将噪声图像逐渐还原的方式来生成清晰图像的。
还有一个很简单的逻辑:我们知道 AI 绘画常常画不好人物的手,会出现手指粘连在一起或者一只手有六七八根手指的情况。假设 AI 绘画真的是通过拼接图像的部分来生成图像,那么它就应该能够画出完美的手,因为它可以直接从训练数据中找到完美的手的部分来拼接。但实际上,AI 绘画并不能画出完美的手。这就说明 AI 绘画并不是通过拼接图像的部分来生成图像的。
💭 个人观点
从个人的角度,我能够理解这种愤怒。但是,我认为我们应该首先了解 AI 绘画的原理,然后再对它进行批评。否则,我们的批评就会变得毫无意义。
不可控?
有人说 AI 绘画是不可控的,因为我们无法控制它生成的图像。这种说法也不完全正确。实际上,在现阶段,任何一个 AI 模型都是一套固定的算法参数,但是人为引入了随机性。只要我们控制所有的输入参数不变,我们就可以得到相同的输出。这是算法的基本特性,也是我们能够对 AI 模型进行训练和调参的基础。
但在一定程度上,这种说法也有它的道理。相同的文本提示词可能会生成出不同的图像,这是因为我们引入了随机性来增加生成图像的多样性。而且,由于前文所述的训练和生成原理,我们无法通过文本提示词来精确地控制图像的细节。
我们为什么抵制 AI 绘画?
这一段其实写得不太好,我会在后续的版本中进行修改。
⚠️ 警告
本节内容仅代表个人观点。
在上文中,我们已经了解了 AI 绘画的基本原理。其实,从技术角度来看,AI 绘画并没有什么不妥,反而还是一个有趣的工具。试想一下,如果作为普通人能够让 AI 学会如何画出我们的想象中的图像,那么我们就可以通过 AI 绘画来实现我们的创作想法,而不用担心自己的绘画技术不够好。这是非常令人兴奋的一件事情,对于绘画界来说也是一个很好的发展机会。
因此,我们抵制 AI 绘画并不是抵制这项技术本身。那我们到底在抵制什么呢?我认为最主要的矛盾在于 AI 绘画的商业化。
我们来分析一下 AI 绘画的商业化导致的问题。
首先,AI 绘画的训练数据集大多由互联网上的公开资源组成,这些资源通常没有得到画师的许可就以“学术研究”的名义被获取;然而待训练完成后,这些模型的相当一部分就会被用于商业目的。这实质上是一种侵权行为,因为画师的作品被用于商业目的而没有得到相应的报酬。
其次,AI 绘画的商业化导致了原创作品的价值下降。画师的作品是独一无二的,因为每个画师都有自己独特的风格和创作理念。AI 绘画可以生成大量的图像,对于未经训练的大部分观众,他们几乎无法从视觉上区分出哪些是 AI 生成的,哪些是画师创作的(而且随着技术的进步会更难以区分)。这就导致了画师的作品价值下降,从而进一步影响了画师的创作积极性。
最后,AI 绘画的商业化导致了画师的就业机会减少、市面上插画质量变低。画师们曾经可以通过创作作品来获得收入,但是现在很多公司、机构更愿意使用 AI 生成的图像而不是画师创作的图像:因为 AI 的出图效率更高,而质量成为了在高效率出图之下可以舍弃的东西。这就导致了画师的就业机会减少,同时市面上充斥着大量的低质量 AI 插画。而且,由于上述的侵权行为,画师的作品还被用于商业目的而没有得到相应的报酬,让本就不富裕的画师们更加难以维持生计。
因此,我们抵制的是 AI 绘画的商业化,而不是技术本身。我们希望 AI 绘画能够成为一个有益于绘画界的工具,而不是一个剥夺画师权益的工具。
结语
AI 绘画是一项有趣的技术,它为绘画界带来了新的发展机会。然而,AI 绘画的商业化却给画师们带来了很大的困扰,甚至是让他们失去了生计。我们现在抵制 AI 绘画,并不是抵制这项技术本身,而是抵制它的商业化。我们希望 AI 绘画能够成为一个有益于绘画界的工具,而不是一个剥夺画师权益的工具。
技术开发者们上应当与画师们团结一致,共同抵制 AI 绘画的商业化。在这场与商业和资本的博弈中,我们都是被剥削的一方,我们应当团结起来,共同抵制商业化的侵权行为。
希望这篇文章可以消除一些误解、带来一些认识、引发一些思考。如果你还有什么建议或者想骂我的话请在评论区留言或者在侧栏链接里发邮件给我。
[^1]: AARON - Wikipedia
[^2]: Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative Adversarial Networks. arXiv preprint arXiv:1406.2661.
[^3]: Sohl-Dickstein, J., Weiss, E. A., Maheswaranathan, N., & Ganguli, S. (2015). Deep Unsupervised Learning using Nonequilibrium Thermodynamics. arXiv preprint arXiv:1503.03585.

